TL;DR:
- Used Max to port a minimal implementation of yolo v8 nano extracted from Ultralytics lib.
- Accuracy is lower compared to the PyTorch model, I suspect: InterpolationMode, only BICUBIC is available from Max, PyTorch could be using BiLinear or Nearest.
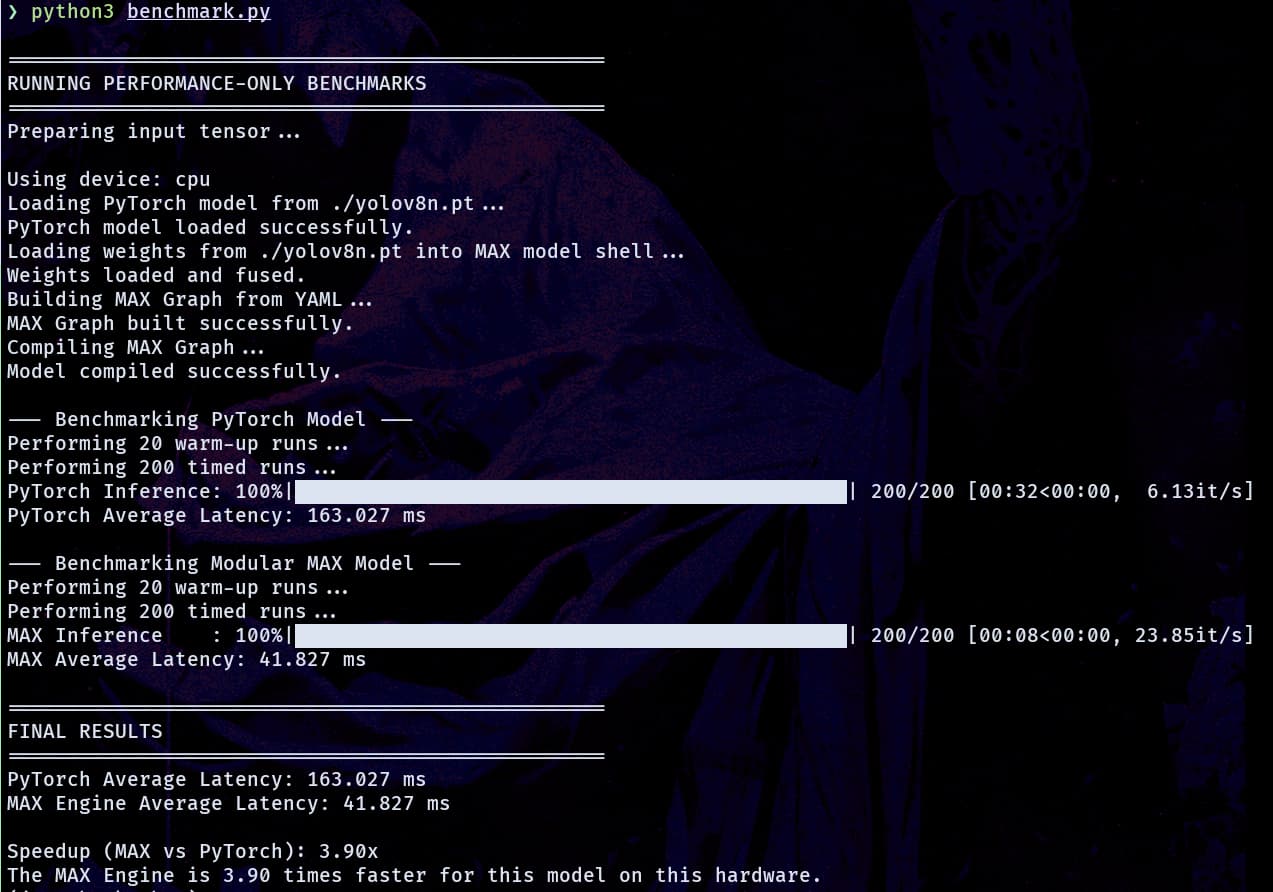
- On the Inference Benchmark, it is showing at least 3x the improvement.
- On the Accuracy Benchmark, it is always low, so I didn’t add it.
Note: AI is heavily used in this; if you find any inaccuracy, pls feel free to correct.
Appreciation: shoutout to kapa.ai for answers.
Github URL: june-hackathon
Benchmark Results
Detailed Difference between PyTorch and Max Implementation.
High-Level Answer: Is the Change Significant or “Meh”?
The change is highly significant. It’s not just a minor syntax update—it represents a fundamental shift in the execution paradigm:
- PyTorch: Uses an eager execution model. Networks are defined and run dynamically, operation by operation—ideal for flexibility and research.
- Mojo/Modular MAX: Uses a graph-based, ahead-of-time (AOT) compilation model. It defines computation as a static graph using Python syntax, which is then compiled by the MAX Engine into a highly optimized binary targeting specific hardware.
Think of it like this:
- PyTorch (Eager): An interpreter reading and executing your code line-by-line.
- Modular MAX (Graph): A compiler that analyzes and optimizes your program into a fast, standalone application.
Detailed Breakdown of Key Changes
1. The Core Engine: torch vs. max
PyTorch:
- Uses
torchandtorch.nn. - Executes ops immediately via the PyTorch runtime.
import torch.nn as nn
# This object IS the runnable layer
conv_layer = nn.Conv2d(3, 64, 3)
output = conv_layer(input_tensor) # Execution happens here
Modular MAX:
- Uses
max.graph.opsto build a graph (no immediate execution).
from max.graph import ops
# This object DESCRIBES a convolution
conv_out = ops.conv2d(x, self.weight, ...) # Adds a node to the graph
# No computation has happened yet.
2. Model Definition: nn.Module vs. Graph-Building Classes
PyTorch:
- Uses
nn.Modulesubclasses (Conv,C2f,SPPF) containing layers andnn.Parameters. - The
forwardmethod defines dynamic logic.
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), ...)
self.bn = nn.BatchNorm2d(c2)
# ...
def forward(self, x):
return self.act(self.bn(self.conv(x)))
Modular MAX:
- Defines custom classes like
MaxConv,MaxSPPFthat describe the computation.
class MaxConv:
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True, name_prefix=""):
self.weight = Weight(name=f"{name_prefix}.conv.weight", ...)
self.bias = Weight(name=f"{name_prefix}.conv.bias", ...)
# ...
def __call__(self, x):
conv_out = ops.conv2d(x, self.weight, ...)
biased_out = conv_out + self.bias.to(x.device).reshape(...)
return self.act(biased_out)
3. Weight Handling: Direct Loading vs. Fusion
PyTorch:
- Loads weights with
state_dict; BN is separate.
model.load_state_dict(state_dict, strict=True)
Modular MAX:
- Explicitly fuses BatchNorm into Conv weights (for inference optimization).
# Fusing Conv + BN
bn_weight_key = f"{bn_prefix}.bn.weight"
if bn_weight_key in state_dict:
# ... math to fuse bn_w, bn_b, bn_rm, bn_rv into conv_w ...
fused_w = conv_w * scale.view(-1, 1, 1, 1)
fused_b = bn_b - bn_rm * scale
fused_weights_temp[target_key] = fused_w.numpy()
fused_weights_temp[target_bias_key] = fused_b.numpy()
4. Inference Pipeline: Implicit vs. Explicit Compile
PyTorch:
- Simple pipeline:
eval()+ inference.
model = load_yolo_model_from_pt(...)
model.eval()
with torch.no_grad():
predictions = model(image_tensor)
Modular MAX:
- Requires an explicit compile step before execution.
max_model = load_yolo_model_from_pt(...) # Loads weights into placeholders
session = engine.InferenceSession() # Creates a runtime session
max_model.compile(session) # <-- THE CRITICAL COMPILE STEP
processed_output = max_model(max_tensor) # Executes compiled graph
5. Data Handling: torch.Tensor vs. max.driver.Tensor and NumPy
PyTorch:
- Entire pipeline uses
torch.Tensor.
Modular MAX:
- Uses
max.driver.Tensorinternally. - Requires conversion from NumPy → max Tensor → NumPy (for post-processing).
- Post-processing (like
dfl_numpy,dist2bbox_numpy) is written in pure NumPy.
Conclusion
The Mojo/Modular MAX script is a re-architecture, not a rewrite.
| Feature | PyTorch Script (Eager Execution) | Mojo/Modular Script (Graph Compilation) | Significance |
|---|---|---|---|
| Paradigm | Dynamic, flexible, interpreter-like | Static, optimized, compiler-like | Massive |
| Core Lib | torch.nn |
max.engine, max.graph |
Massive |
| Model Code | Defines runnable nn.Modules |
Defines graph-describing classes | Significant |
| Weights | Loads weights directly, BN is separate | BN is fused manually into Conv layers | Significant |
| Inference | model(tensor) |
session.compile(), then model.execute() |
Significant |
| Post-Proc | Done with Torch tensors | Done with NumPy arrays | Minor |
Final Thoughts
This Mojo/Modular MAX implementation is an excellent example of moving a model from a flexible research framework (PyTorch) to a production-grade, high-performance system using AOT compilation. The changes aren’t just about performance—they represent a full stack shift from dynamic to optimized execution.
–
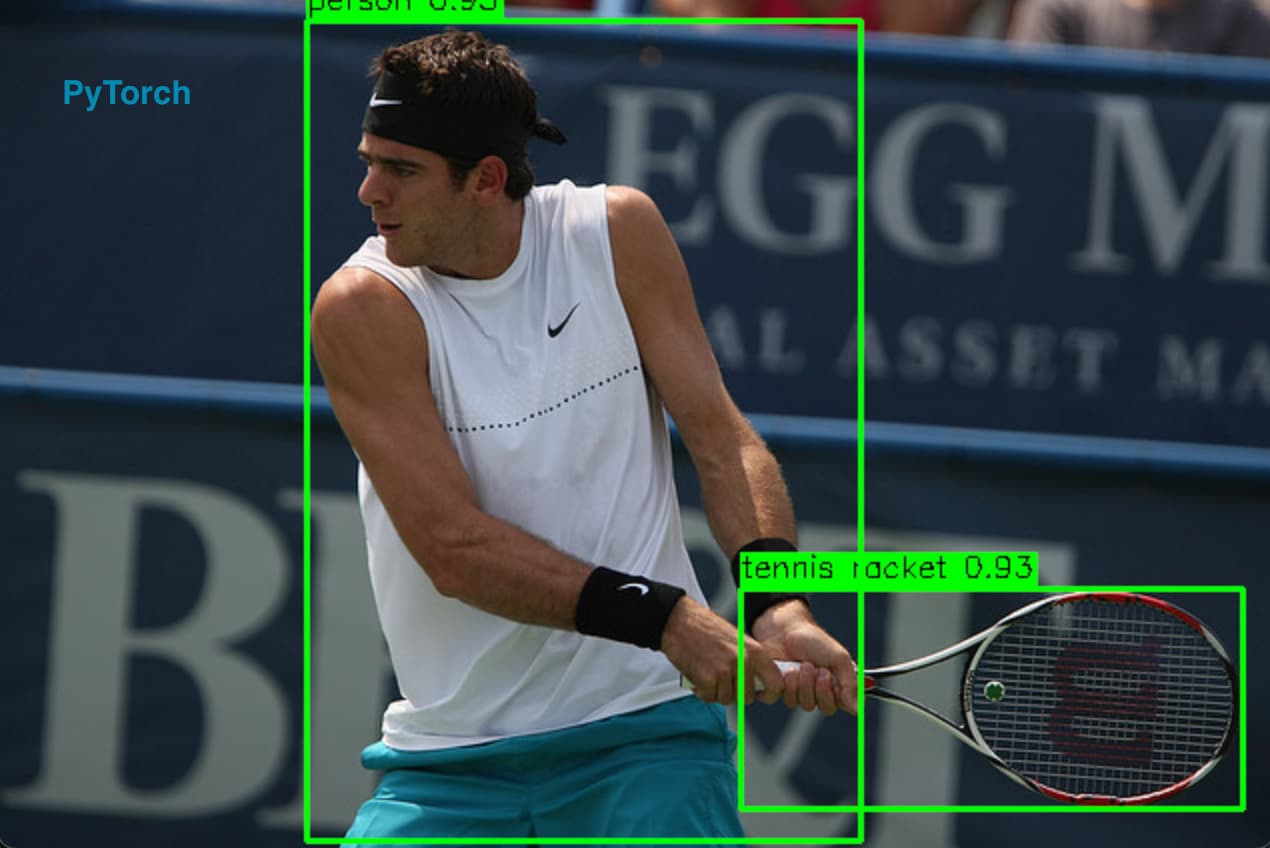
Outputs:
PyTorch

Max


