Hi everyone.
I haven’t touched my llama2.![]() github repo for a long time. More precisely since March 2024
github repo for a long time. More precisely since March 2024
I have finally refactored this legend today. Mojo compiler ver is 0.25.7.0
https://github.com/tairov/llama2.mojo
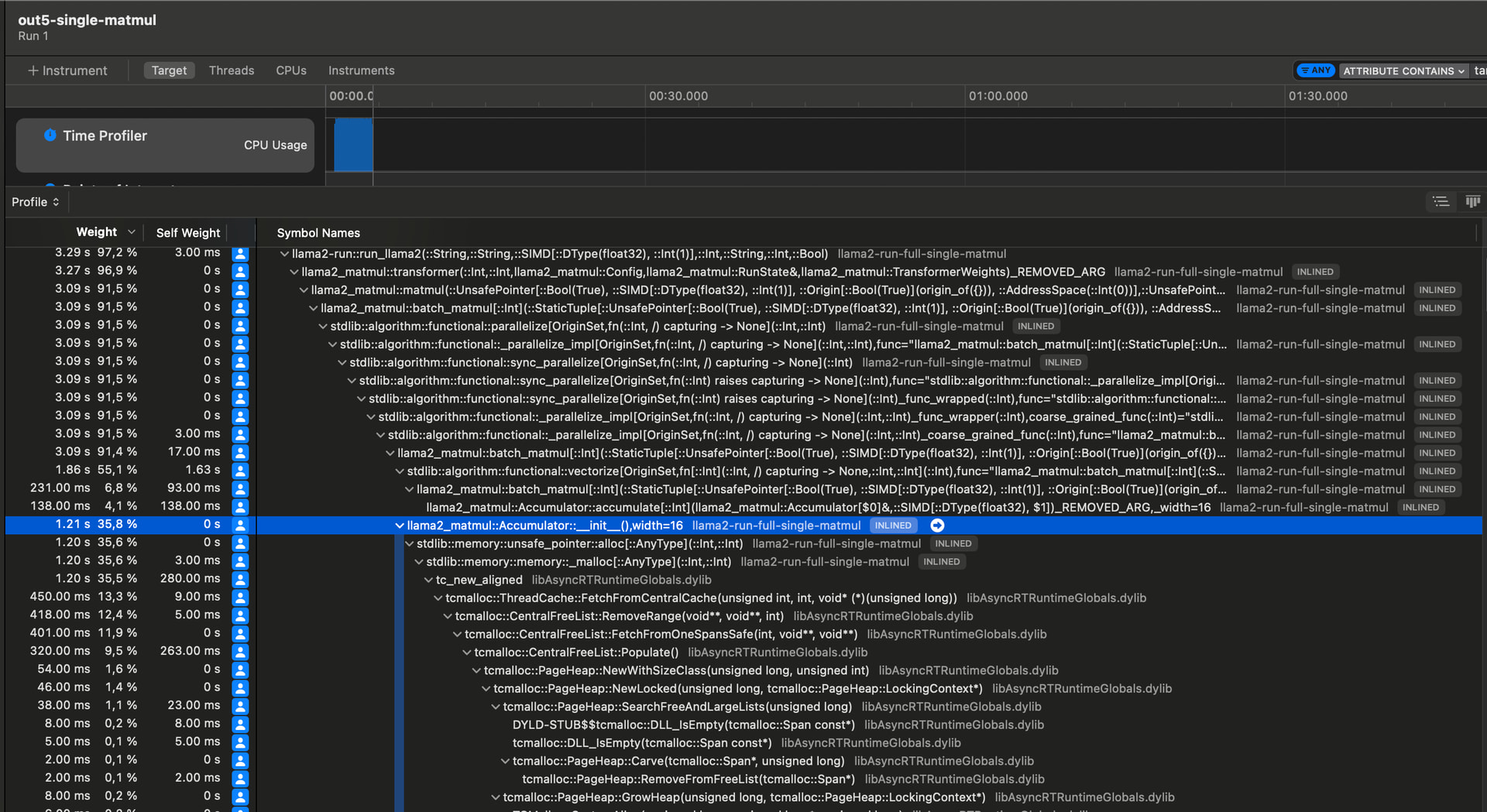
What I have immediately noticed - is the significantly degraded performance ![]()
Onstories15M.bin model on my Mac M1 - it shows ~170 tokens/sec throughput ..
Though on Mojo version 24.3 it shows ~1000 tok/sec…
yes, I still have a Mojo compiler from March 2024
Ofc, I might have some parts of the calculations done not in optimal way, not sure, still need to investigate..
Most of the SIMD calculations are done over UnsafePointers, avoiding any heavy data copying, so essentially it reproduce similar approach I used in first versions of llama2, using custom struct Matrix
So I don’t see any reasons why the code itself might be not optimal.
If anyone from the Mojo compiler team could have take a look and share insights on why there’s such a severe degradation ( and probably how to fix it ![]() ) I’d really appreciate it
) I’d really appreciate it
Just in case older version code is here - GitHub - tairov/llama2.mojo at old-mojo-24.3