Based on your questions I watched this talk:
Which kind of send me back to the drawing board 
The radix sort I implemented is a “generic” copying LSB Radix sort for Scalar values, I do handle uint, int, and float, hence I call it generic, but it is not like you can sort any kind of data with it, just scalar numbers.
Radix11/13/16 is an alternative implementation based on this article stereopsis : graphics : radix tricks which is also a copying LSB Radix sort, with different computation of histogram (making it wider 11, 13, or 16 bits instead of 8), all the histograms are computed at the same time, the counts/offsets per bucket are computed a bit differently than the standard prefix sum and the temp memory is 2x compared to the typical Radix sort.
When we take a look at the benchmark report we can see that the Radix11 can be about 2x faster than my generic radix sort (Keep in mind that Radix11 only works on 32bit wide numbers). And the Radix13/16 variant (which wokrs on 64bit wide numbers) is also about 1.5x faster then the generic one, where the 16 variant seems to be not better than the 13 variant.
Additionally I also implemented a copying MSB Radix sort algorithm specifically for string sorting. The implementation is from 2024 I just made it compile again and did not spend more time with it to check if there are some bottlenecks I can avoid. The benchmark from 2024 shows that std sort is almost always faster than the radix sort by about 2x.
This is what I currently have and now comes what I need to do after I watched the talk linked above.
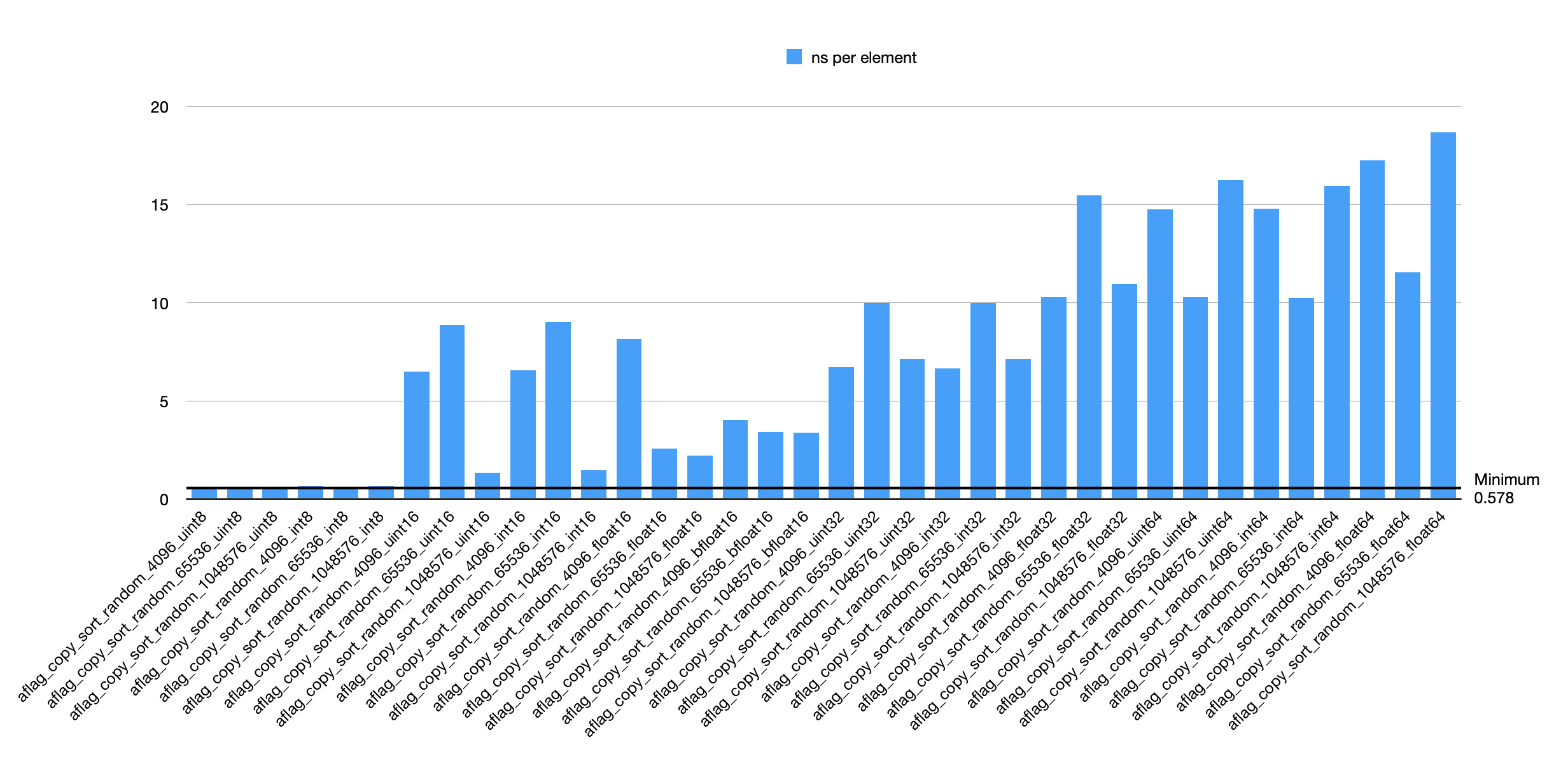
I need to implement American Flag sort which is an in place variant of MSB Radix sort (in place means no additional temp memory allocation, only a stack allocation for the histogram). Then compare it to my copying Radix sort implementation.
Next look at the Ska sort implementation, from the speaker of the talk and implement this. His implementation is more generic, allowing to provide the algorithm with partitioning value if you will. I need to study how he does it and if it is applicable in current state of Mojo.
The generalization effort is kind of orthogonal to the sorting algorithm itself.
One other thing I’d like to see the primitive used for is that I’ve seen radix sort used to minimize the amount of comparisons of another algorithm by sorting each of the buckets using a different key function or by making each bucket a heap. This can also help cut down on the number of buckets.
@owenhilyard could you point me to this algorithms. Until now I see optimizations which go toward increasing the number of buckets instead of reduction, this would be an interesting avenue to explore.
As always, sorting turns out to be quite a rabbit hole.
: Generalizing and optimizing radix sort\"")