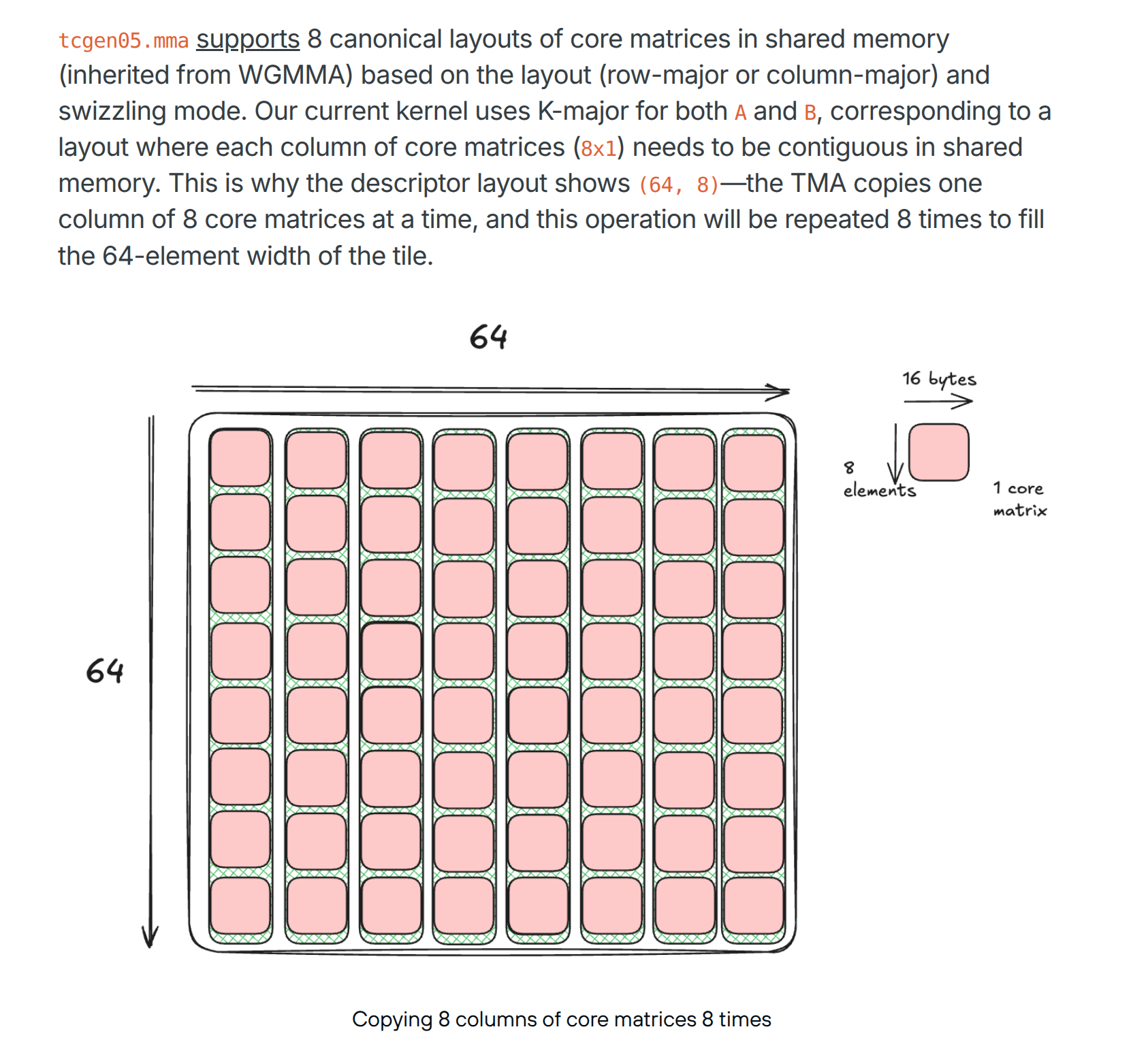
I had a great time reading the Mojo SOTA Blackwell matmul blog series and learned a lot about newest GPU features and architecture. While digging more deeply into each part, I’m currently confused about TMA loading from global to shared memory in part 2. In particular this explanation about consecutive TMA load operations
What confused me is since A and B matrix are both K-major (which means row-major), how does the columns of the matrix cores end up being contiguous in memory, shouldn’t it be the rows of the matrix cores instead?
This was brought up before. I think we’re following the nvvm instrinics nvvm.cp.async.bulk.tensor.shared.cluster.global as well as the PTX instruction so the API becomes confusing. @JXL should we follow making the API more user friendly?
I’m not familar with lower ptx instructions or nvvm intrinsics yet. Are you saying that even though the data is stored with row-major layout in shared memory and global memory, the TMA will load columns of matrix cores from global memory at a time (as illustrated in the picture)?
That’s right and is confusing! By referring to nvvm and PTX I meant basically we’re following the nvidia conventions now. Through that we’re seeing how to make the APIs more user friendly so these feedbacks are great. We’ll resolve them soon.