Hi, I’m Thomas,
I’m excited to share my first project in Mojo and my first experience with GPU programming. As a final-year Master’s student in Computer Science specializing in AI, I’ve always been passionate about CPU parallel computing and was eager to explore GPU programming. I developed QLabs, a Quantum Circuit Simulator with GPU support, for the Modular Hack Weekend. This project builds on my prior CPU-based implementation, inspired by the research paper “How to Write a Simulator for Quantum Circuits from Scratch: A Tutorial” by Michael J. McGuffin et al., published this month.
Firstly, the impact of QLabs lies in its educational value, offering an accessible, Pythonic interface for deeply exploring and experimenting with quantum computing concepts, and its novelty as the first quantum circuit simulator in Mojo with GPU acceleration. Secondly, its adaptable design, leveraging efficient primitive functions like qubit_wise_multiply() on GPU, democratizes access to high-performance and flexible quantum simulation.
GitHub Repository: GitHub - ttrenty/QLabs: A Quantum Circuit Composer & Simulator In Mojo 🔥⚛️
Description and Discussion
This simulator is a new project, with my initial CPU implementation developed in just four days.
QLabs offers two levels of abstraction:
-
Low-level: Implements functions and techniques from McGuffin et al.'s paper (~1,500 lines of code).
-
High-level: Enables intuitive circuit creation and execution with a single line of code (~800 lines of code).
For the hackathon, I focused on adding GPU support for the core low-level function qubit_wise_multiply(), which computes the new quantum state of a circuit given the current state (defined by a State Vector) and a gate applied to the circuit in a noiseless setting. This function avoids matrix calculations, instead using efficient techniques described by McGuffin et al. for optimized quantum simulation. My goal was to enable seamless switching between CPU and GPU implementations at the high-level abstraction, which I accounted for during the GPU development of this low-level function.
We currently support only one GPU at the time, but we automatically scale the maximum number of threads per block to the maximum allowed by the current GPU by reading the DeviceContext.device_info.max_thread_block_size field and allocating as many threads per block as necessary.
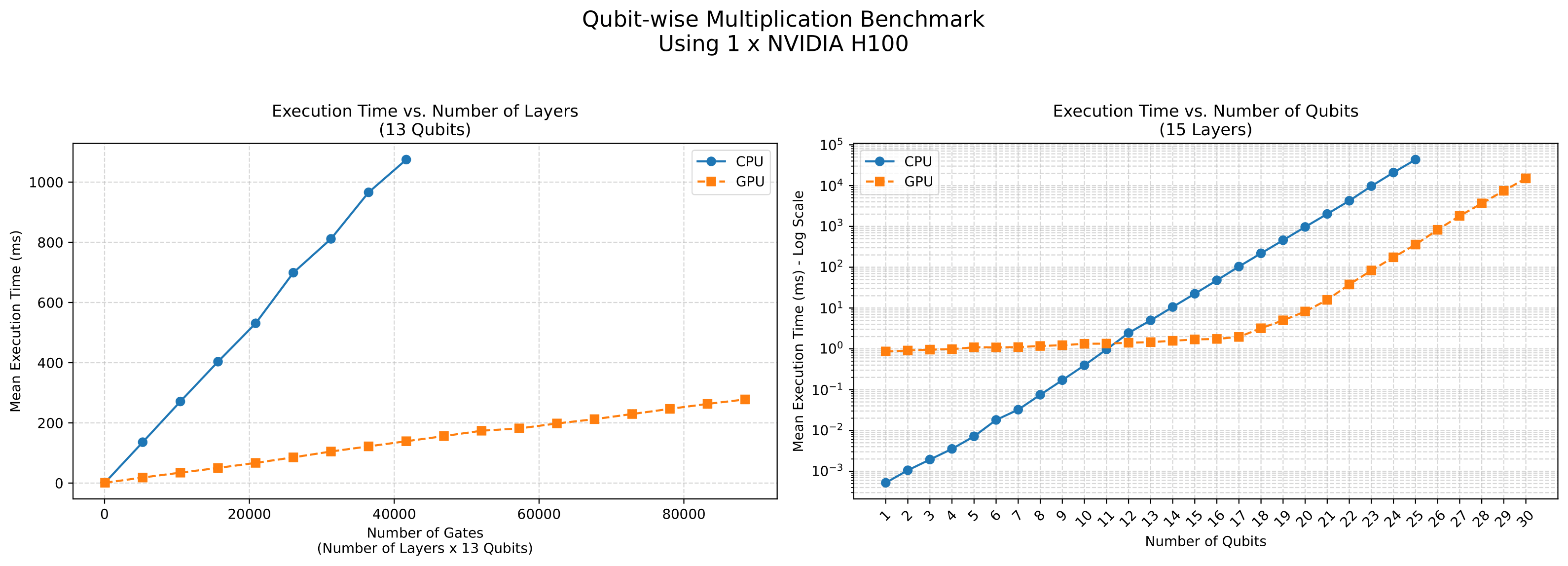
I validated the GPU implementation by comparing its effect on quantum states with the CPU version, which was verified against McGuffin et al.'s paper and another simulator, PennyLane. Benchmarks comparing CPU and GPU performance show significant speedups with GPUs starting at 12 qubits, as shown in the plot below. The GPU implementation using a NVIDIA H100 achieves 100x faster executions for 18 qubits and above compared to the CPU implementation. This is due to the high independence of state vector elements, allowing one GPU thread per new element. The number of elements in the state vector scales as 2^num_qubits, as does the total number of GPU threads in the GPU grid.
We use only two state vector buffers to store the quantum states during execution of the circuit, storing the current and next quantum states and swapping their roles after each operation. This ensures all GPU data is initialized at circuit declaration, enabling immediate computation of quantum gate operations one after another on the GPU. However, this initialization contributes to slower performance with a low number of qubits.
During GPU development, I encountered bugs in Mojo, notably one involving List variables defined as aliases, which Austin Doolittle helped resolve by defining the List as an actual variable instead. I plan to report these bugs after the hackathon.
More Details
The pixi.toml file in the GitHub repository makes heavy use of caching for task results, and it was a pleasure to work with pixi during development. I created a Makefile to map my make commands to pixi run for convenience, as it’s easier to type.
My time during the hackathon was spent as follows (not by design, but reflecting the challenges encountered, given my starting point of a CPU implementation and limited GPU experience):
-
65%: Setting up buffers and tensors, including their layout and mapping CPU data to GPU data, converting arguments to parameters, and making use of aliases for compile time declarations.
-
10%: Debugging runtime bugs with unclear error messages, such as this issue.
-
10%: Implementing the GPU kernel for
qubit_wise_multiply(). Mojo made this remarkably straightforward, though the kernel has room for optimization. The real challenge was setting up the surrounding infrastructure. I regret not having time to implement GPU support for the other low-level functionsqubit_wise_multiply_multiqubits(),apply_swap(), andpartial_trace(), but these should be feasible with similar effort. -
10%: Creating tests, benchmarks, plot generation scripts.
-
5%: Miscellaneous tasks.
What’s Next?
This project marks the beginning of GPU support for QLabs, with more features to be implemented. QLabs aims to provide an accessible approach to quantum circuit simulation for those curious about diving deeper into quantum computing. Compared to McGuffin et al.'s JavaScript implementation, QLabs offers a Pythonic syntax and adds GPU support, providing a accessible approach for learners.
While efficient, the simulator lacks some functionality. Once more features are added for CPU and GPU, I plan to benchmark it against other quantum circuit simulators for a fairer comparison. In the future, integrating Mojo/MAX with open-source simulators like PennyLane, which already supports NumPy, JAX-JIT, PyTorch, and TensorFlow, would be interesting. However, given my lack of GPU programming experience before the hackathon, this was too ambitious for this event.